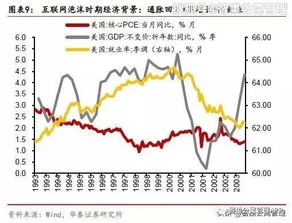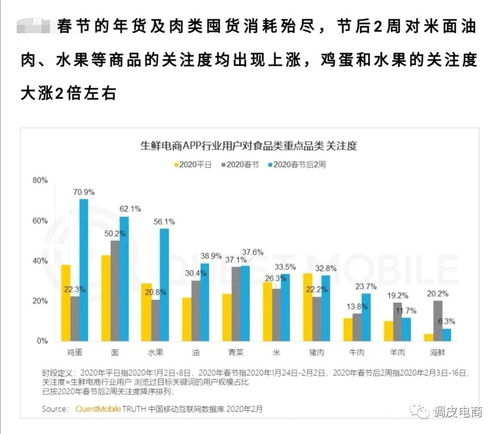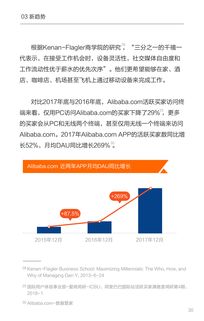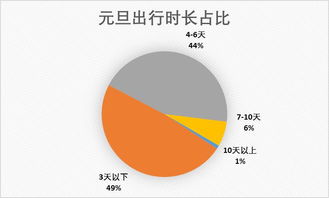
全球13家知名媒體機構聯合起訴OpenAI等人工智能巨頭,指控其未經授權大量使用新聞內容訓練大語言模型,引發了關于AI與內容版權邊界的激烈辯論。這一事件不僅凸顯了技術發展與知識產權保護之間的深刻矛盾,更揭示了互聯網時代內容創作價值被侵蝕的隱憂——當AI將海量數據視為“免費午餐”,原創者的權益該何去何從?
一、事件核心:媒體的憤怒與AI的“數據饑渴”
這些媒體指控,OpenAI、微軟等公司通過爬蟲技術抓取數百萬篇新聞文章、深度報道和調查內容,用于訓練如GPT-4等大模型,使其能夠生成類似風格的文本、回答實時問題,甚至模仿媒體品牌的聲音。整個過程未經許可、未支付費用,也未明確標注來源。媒體認為,這無異于“系統性盜竊”,侵蝕了新聞業的生存基礎——內容價值。而AI公司則多引用“合理使用”原則辯護,稱訓練行為屬于轉換性使用,旨在推動技術創新與公眾利益。
二、法律拉鋸戰:“合理使用”與“版權侵權”的灰色地帶
爭議焦點在于對“合理使用”條款的解讀。美國版權法規定,為評論、教學、研究等目的有限使用版權作品可能不構成侵權。AI公司主張,模型訓練是對數據的“學習”而非“復制”,生成內容屬于新作品。但媒體反駁:大規模商用性使用、直接抽取核心內容(如事實報道)且對原市場造成替代效應,已超出合理范圍。歐盟《數字服務法》等新規正試圖收緊數據使用規范,但全球立法仍滯后于技術步伐,形成灰色地帶。
三、內容創作者的困境:從“價值核心”到“數據燃料”
互聯網早期,開放共享精神催生了海量免費內容,但如今AI的崛起加劇了內容貶值的惡性循環:創作者投入時間與成本生產優質作品,卻被視為可隨意開采的“數據礦藏”。大模型通過消化這些內容獲得商業收益,而原創者既未獲得經濟回報,還可能面臨AI生成內容的競爭沖擊。這種不對稱關系,使得創作激勵受損,長遠可能削弱內容生態的多樣性與質量。
四、互聯網數據服務:是基礎設施還是剝削工具?
AI巨頭依賴的互聯網數據服務,本質上構建于數十年的開放網絡內容之上。但若將整個互聯網視為“免費訓練場”,則可能扭曲數據經濟的倫理框架。部分公司已嘗試與媒體合作付費授權(如OpenAI與美聯社協議),或開發更透明的數據溯源技術。這些舉措尚未成行業標準,小規模創作者更是缺乏議價能力。如何建立公平的數據價值分配機制,成為亟待解決的系統性課題。
五、未來路徑:在創新與保護之間尋找平衡
這場訴訟可能成為AI版權史的里程碑事件。可能的解決方案包括:
- 立法明確邊界:更新版權法,細化AI訓練數據的使用規則,區分科研與商用場景;
- 技術賦能協議:推廣“選擇退出”機制,允許網站拒絕爬蟲,并發展版權管理工具;
- 新型合作模式:AI公司通過許可費、收入分成或數據貢獻認可反哺內容產業;
- 行業標準共建:內容平臺、創作者與科技企業協同制定數據倫理準則。
重塑數字時代的“創作契約”
13家媒體的抗爭,不只是法律訴訟,更是對數字時代價值分配的一次拷問。AI的進步不應以犧牲創作者權益為代價,而互聯網的“免費精神”也需進化為“公平共享”的新范式。唯有在技術創新與人文關懷之間找到平衡,才能讓數據真正服務于人類整體福祉,而非成為少數巨頭的壟斷資本。這場博弈的結果,將深遠定義未來知識生產的規則與尊嚴。